
Prompt Engineering; Effective interaction with AI models
August 22, 2023
Using Large Language Models (LLMs) and Haystack for AI-Powered Customer Support Automation
October 31, 2024Introduction to Kafka as a Streaming Platform
In the realm of modern data architecture and event-driven systems, Apache Kafka stands out as a powerful and versatile streaming platform. Kafka has gained immense popularity for its ability to handle real-time data streams efficiently and reliably. In this article, we will explore Kafka's unique features, its role as a central nervous system for organizations, and its distinct advantages over traditional messaging systems and databases.
The Rise of Event-Driven Systems
The concept of event-driven systems has become increasingly important in the world of software engineering. Event-driven architectures focus on processing events or messages as they occur, allowing applications to react promptly to changing conditions. This paradigm shift has been driven by the need for real-time data processing, scalability, and flexibility in modern applications.
Practical Example: Imagine an e-commerce platform that needs to notify customers of product price drops. In a traditional request-response system, customers would have to refresh the product page to check for price changes. However, in an event-driven system powered by Kafka, the platform can publish price change events in real-time. Customers subscribe to these events, and when a price drop event occurs, they receive an immediate notification, providing a better user experience.
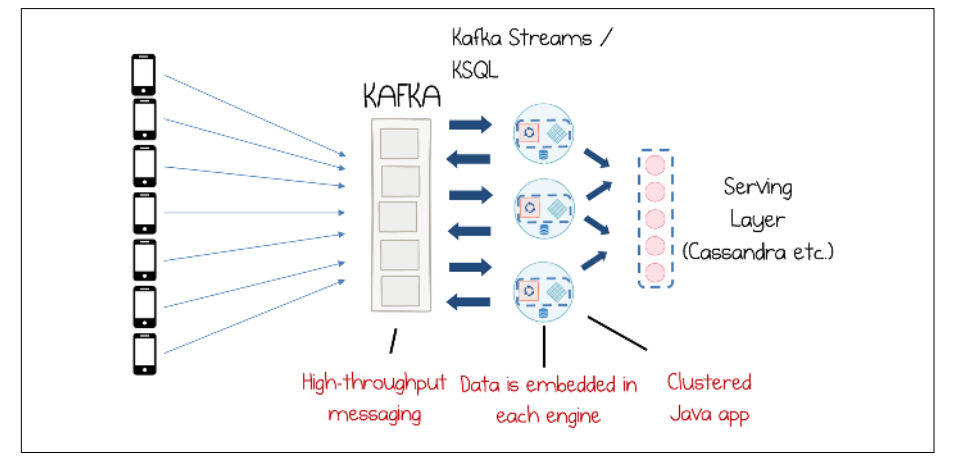
A typical streaming application that ingests data from mobile devices
into Kafka, processes it in a streaming layer, and then pushes the result to a serving
layer where it can be queried
Kafka's Origins and Architecture
Apache Kafka was originally developed at LinkedIn and open-sourced as an Apache project. At its core, Kafka is a distributed event streaming platform that excels in handling high-throughput, fault-tolerant data streams. It consists of a cluster of Kafka brokers, which store and distribute events, and client APIs that allow developers to interact with the Kafka ecosystem.
Kafka's distributed nature ensures scalability and fault tolerance. It can seamlessly handle large volumes of data while maintaining data integrity and availability. This makes it a robust choice for building event-driven applications and services.
Practical Example: Suppose you work for a logistics company that needs to track the real-time location of delivery trucks. Kafka's distributed architecture allows you to collect GPS data from thousands of trucks. The Kafka brokers store and distribute this location data efficiently, ensuring that it's available for real-time tracking and historical analysis. This architecture ensures fault tolerance, scalability, and data integrity, even if individual truck sensors or Kafka brokers experience issues.
Kafka's Streaming Capabilities
Kafka extends its capabilities beyond message brokering by offering powerful streaming features. Two key components, Kafka Streams and KSQL, enable real-time data processing. Kafka Streams allows developers to build applications that process data streams in real-time, supporting operations like filtering, joining, and aggregation. KSQL, on the other hand, provides a SQL-like interface for stream processing, making it accessible to data analysts and engineers with SQL expertise.
Practical Example: Consider a financial institution that needs to detect fraudulent transactions in real-time. Kafka Streams can be employed to process a continuous stream of transaction data. Using Kafka Streams, you can filter transactions, identify patterns indicative of fraud, and trigger alerts or block suspicious transactions immediately.
Connectivity and Integration
Kafka's ecosystem includes connectors that facilitate data integration with external systems. These connectors enable data extraction from various sources and the seamless injection of data into Kafka topics. This flexibility empowers organizations to unlock hidden datasets and transform them into valuable event streams.
Practical Example: Let's say you manage a healthcare organization that needs to integrate patient records from various legacy systems into a unified platform. Kafka's connectors can simplify this process. You can use connectors to extract patient data from diverse data sources, such as older databases and electronic health record systems, and stream this data into Kafka topics. This integration ensures that real-time patient information is available to healthcare providers.
Use Case: Real-time Fraud Detection in Financial Transactions
Scenario: Imagine you work for a large financial institution, like a bank or credit card company, and your primary concern is to detect and prevent fraudulent transactions. This is a critical task as it helps protect both the financial institution and its customers from potential financial losses. Traditional batch processing or request-response systems may not be sufficient for this purpose, as fraudsters are becoming increasingly sophisticated. To address this challenge, you decide to implement Kafka as the backbone of your real-time fraud detection system.
How Kafka is Utilized:
- Data Ingestion: Financial transactions, such as credit card swipes, ATM withdrawals, and online purchases, generate vast amounts of data. These transactions are sent in real time to Kafka topics as events. Each transaction event contains relevant information, such as the cardholder's details, transaction amount, location, and timestamp.
- Event Processing: Kafka Streams, part of the Kafka ecosystem, is used to process these transaction events in real time. The stream processing application continuously analyzes incoming transactions as they flow through Kafka.
- Fraud Detection Logic: Within the Kafka Streams application, sophisticated fraud detection algorithms are applied to identify potentially fraudulent transactions. These algorithms consider various factors, such as unusual spending patterns, geographic anomalies (e.g., transactions from two distant locations in a short time), and behavioral analytics.
- Alert Generation: When a potentially fraudulent transaction is detected, an alert event is generated in Kafka. These alerts can trigger various actions, including notifying the cardholder through SMS or email, temporarily blocking the card, or initiating a review by the bank's fraud investigation team.
- Historical Data Storage: Kafka's ability to store data for a specified retention period is invaluable for fraud detection. It allows investigators to access historical transaction data when reviewing suspicious cases or conducting forensic analysis.
from kafka import KafkaConsumer, KafkaProducer
# Initialize Kafka consumer and producer
consumer = KafkaConsumer('transaction_data', bootstrap_servers='localhost:9092')
producer = KafkaProducer(bootstrap_servers='localhost:9092')
# Define fraud detection logic function
def detect_fraud(transaction):
# Implement your fraud detection algorithm here
if transaction['amount'] > 1000:
return True
return False
# Continuously process incoming transactions
for message in consumer:
transaction = message.value
if detect_fraud(transaction):
# Generate an alert event in Kafka for potential fraud
producer.send('fraud_alerts', value=transaction)Benefits:
- Real-time Detection: Kafka's streaming capabilities enable the system to detect fraudulent transactions as they happen, reducing the financial institution's exposure to losses.
- Scalability: Kafka's distributed architecture ensures that the system can handle a high volume of transactions, making it suitable for large financial institutions with millions of customers.
- Flexibility: The Kafka ecosystem provides a wide range of connectors, allowing integration with various data sources, including transaction terminals, databases, and external fraud detection services.
- Fault Tolerance: Kafka's fault tolerance ensures that even in the event of hardware or software failures, the system can continue to process transactions and generate alerts.
- Data Retention: Historical data stored in Kafka can be crucial for auditing, compliance, and forensic investigations related to fraud cases.
Apache Kafka Official Documentation: The official documentation provides in-depth information about Kafka's core components and how to use them.
Confluent's Kafka Tutorials: Confluent offers a series of tutorials that cover various aspects of Kafka, from basic concepts to advanced topics.
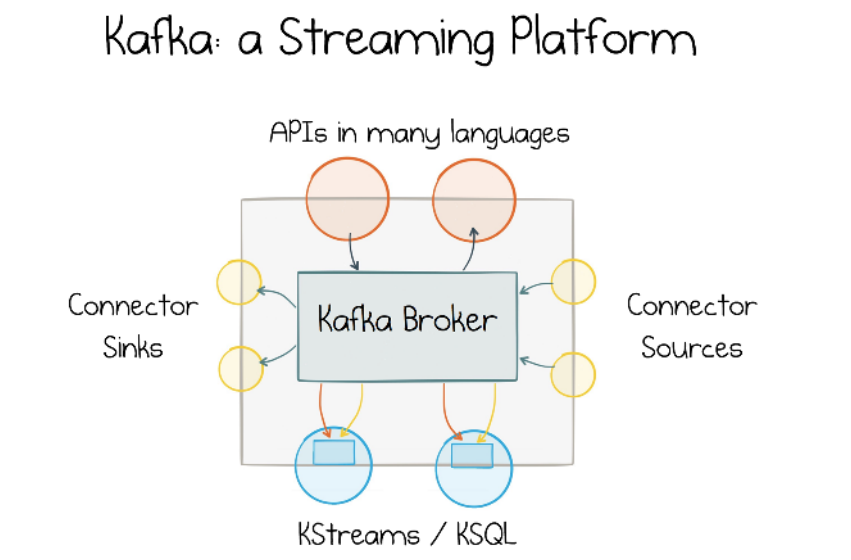
. The core components of a streaming platform
Kafka's Unique Strengths
Kafka offers a set of unique strengths that distinguish it as a streaming platform. One of its core features is its ability to handle high-throughput event streams efficiently. Unlike traditional messaging systems, Kafka provides durability and high availability, making it suitable for mission-critical applications. Kafka clusters can scale horizontally, distributing the load and ensuring seamless data ingestion and processing even in large-scale deployments.
The Kafka ecosystem includes powerful client APIs for various programming languages, making it accessible to a wide range of developers. These APIs allow users to interact with Kafka brokers, publish and subscribe to topics, and perform real-time data processing. Kafka's simplicity and versatility make it an attractive choice for building event-driven architectures.
Kafka Streams and KSQL are two essential components that turn Kafka into a full-fledged streaming platform. Kafka Streams allows developers to write applications that process streams of data in real-time. It supports features like filtering, joining, aggregation, and stateful processing, enabling the creation of complex data processing pipelines. KSQL, on the other hand, provides a SQL-like interface for stream processing, making it accessible to data analysts and engineers with SQL expertise.
Connectors in the Kafka ecosystem facilitate the integration of external data sources and sinks. These connectors enable the extraction of data from various systems and the seamless injection of data into Kafka topics. This flexibility empowers organizations to unlock hidden datasets and transform them into valuable event streams.
Additionally, Kafka provides utilities like Replicator and the Schema Registry. Replicator simplifies the replication of data between Kafka clusters, allowing organizations to create disaster recovery solutions and ensure data availability. The Schema Registry manages data schemas, ensuring consistency and compatibility across applications and services.
Use Case: IoT Data Ingestion and Analytics
Scenario: Imagine you work for a company that manufactures and deploys IoT (Internet of Things) devices, such as temperature sensors in industrial facilities. These sensors continuously collect data and send it to a central server for monitoring and analysis. Your goal is to efficiently collect, process, and analyze this IoT data in real-time to detect anomalies and optimize industrial processes. This is where Kafka plays a crucial role.
How Kafka is Utilized:
- Data Ingestion: IoT devices, equipped with temperature sensors, send temperature readings to Kafka topics as events. Each event includes the sensor's unique identifier, timestamp, and temperature reading.
- Event Processing: Kafka Streams are employed to process these temperature events in real-time. The stream processing application continuously analyzes incoming data as it flows through Kafka.
- Anomaly Detection: Within the Kafka Streams application, you implement algorithms to detect anomalies in temperature readings. For instance, you may look for sudden spikes or drops in temperature that could indicate equipment malfunctions or process issues.
- Alerting: When an anomaly is detected, the Kafka Streams application generates an alert event in Kafka. These alerts can trigger actions like sending notifications to maintenance teams or updating a dashboard for real-time monitoring.
- Data Storage: Kafka's ability to store data for a specified retention period is valuable for historical analysis. You can store all temperature readings in Kafka topics, allowing you to perform offline analytics, identify long-term trends, and generate reports.
from kafka import KafkaConsumer
# Initialize Kafka consumer
consumer = KafkaConsumer('iot_data', bootstrap_servers='localhost:9092')
# Define anomaly detection logic function
def detect_anomaly(temperature):
# Implement your anomaly detection algorithm here
if temperature > 40.0:
return True
return False
# Continuously process incoming IoT data
for message in consumer:
data = message.value
if detect_anomaly(data['temperature']):
# Generate an alert or take action for anomalies
print(f"Anomaly detected: {data}")Benefits:
- Real-time Monitoring: Kafka's streaming capabilities enable you to monitor temperature data in real-time, allowing for immediate responses to anomalies or issues.
- Scalability: As the number of IoT devices and sensors increases, Kafka's distributed architecture ensures that the system can scale horizontally to handle the growing data volume.
- Low Latency: Kafka's low-latency data processing ensures that temperature readings are analyzed and acted upon swiftly, which is crucial in industrial settings where quick responses can prevent equipment damage.
- Fault Tolerance: Kafka's built-in fault tolerance ensures that even in the event of a broker failure, data processing can continue without interruption.
- Historical Analysis: The historical data stored in Kafka provides the ability to analyze temperature trends over time, identify patterns, and make informed decisions about maintenance and process optimization.
Kafka Streams Documentation: Learn about Kafka Streams, the stream processing library in Kafka, and how to build real-time applications.
KSQL Documentation: Explore KSQL, a powerful SQL-like language for querying Kafka topics, with the official documentation.
Kafka's Role as a Central Nervous System
A fitting analogy for Kafka is that it serves as the central nervous system of an organization. Just as the human nervous system connects and coordinates various parts of the body, Kafka connects and coordinates different applications and services within an enterprise. Here's how Kafka fulfills this role:
- Data Integration: Kafka connects disparate systems, databases, and applications, enabling seamless data integration. It acts as a data pipeline that allows information to flow across departments and teams.
- Real-time Processing: Kafka's streaming capabilities enable real-time data processing. Events and messages are processed as they arrive, providing instant insights and enabling immediate actions.
- Scalability and Reliability: Kafka's distributed architecture ensures scalability and high availability. It can handle massive data volumes and continue functioning without interruption even in the face of hardware failures.
- Legacy System Modernization: Kafka's Connectors make it easier to extract data from legacy systems, gradually modernizing the organization's data infrastructure without disrupting existing workflows.
- Stream Processing: Kafka Streams and KSQL allow developers to build applications that react to real-time events. This empowers organizations to create dynamic, event-driven applications and services.
Use Case: Financial Trading and Regulatory Compliance
Scenario: You work for a financial institution that conducts high-frequency trading of stocks and other financial instruments. In the highly competitive and regulated world of finance, it's critical to not only execute trades at lightning speed but also comply with strict regulatory requirements. Kafka plays a pivotal role in addressing these challenges.
How Kafka is Utilized:
- Data Ingestion: Stock market data, including real-time price quotes, trade orders, and news feeds, is ingested into Kafka topics. Multiple data sources, such as stock exchanges and news agencies, continuously feed this data.
- Stream Processing: Kafka Streams and KSQL are employed to process this data in real-time. Stream processing applications are built to calculate indicators like moving averages, identify trading opportunities, and detect potential regulatory compliance issues.
- Trading Decision Making: Traders and algorithms rely on the insights generated by Kafka Streams. For example, if a specific stock's price suddenly drops, a trading algorithm might be triggered to buy shares.
- Regulatory Compliance: Kafka is used to log all trading activities and related data. It acts as an immutable audit trail, recording every trade, order, and communication. This data is crucial for regulatory compliance, including meeting requirements like the Dodd-Frank Act in the United States or MiFID II in Europe.
- Alerting and Reporting: Kafka Streams applications continuously monitor trading activities for compliance violations. If an unusual or suspicious trade is detected, an alert is generated and sent to compliance officers. Kafka also stores compliance-related data for reporting and auditing purposes.
from kafka import KafkaConsumer
# Initialize Kafka consumer
consumer = KafkaConsumer('trading_data', bootstrap_servers='localhost:9092')
# Define trading decision logic and compliance checks
for message in consumer:
trading_data = message.value
# Implement trading decision logic here
if trading_data['price'] < 100.0:
# Execute trading action
# ...
# Implement regulatory compliance checks
if trading_data['regulatory_issue']:
# Generate alert or log compliance issue
# ...Benefits:
- Low Latency: Kafka's low-latency data processing ensures that trading decisions can be made in real-time, taking advantage of market opportunities as they arise.
- Scalability: Kafka's distributed architecture allows for handling vast volumes of data generated by high-frequency trading without sacrificing performance.
- Reliability: Kafka's replication and fault tolerance mechanisms ensure that financial data is highly available and secure against data loss.
- Regulatory Compliance: Kafka's immutable audit trail simplifies regulatory compliance by providing a transparent and tamper-proof record of all trading activities.
- Real-time Analytics: Kafka Streams enable real-time analytics of market data, helping traders make informed decisions and algorithms execute orders efficiently.
- Alerting: Kafka's ability to generate alerts in real-time ensures that compliance officers are promptly notified of any potential violations.
Real-Time Data Streaming for Financial Services with Kafka: This Confluent solution page explains how Kafka is used in the financial services industry for real-time data streaming.
Kafka for Regulatory Compliance: Confluent provides insights into how Kafka can be applied to meet regulatory compliance requirements in the financial sector.
reference: https://kafka.apache.org/documentation/
Kafka as a Streaming Platform
Views: 54



